
Google hates you. Well, at least that’s what you might think if none or too few of your blog posts are indexed. I mean… you spent tons of time working on your content so maybe it deserves to be indexed. So why are only some of my blog posts indexed?
Indexing can take anywhere from a couple hours to a few days, or even a week or more. Websites with huge authority and activity usually get indexed much faster, while new sites can take a little longer. So what if you’re an older site and still not getting indexed? There are quite a few possibilities!

Are You Ready To Work Your Ass Off to Earn Your Lifestyle?
Are you tired of the daily grind? With a laptop and an internet connection I built a small website to generate income, and my life completely changed. Let me show you exactly how I’ve been doing it for more than 13 years.
Answer: Time, SEO Problems, Or Keyword Problems
The main three problems you will probably run into regarding getting indexed are going to be not waiting enough time after publishing, technical SEO problems, or perhaps you’re just writing about stuff no one cares about so Google decided to ignore that page.
New Sites Need Time To Get Indexed
Most of the people I work with are having trouble getting indexed simply because their websites are too new. If you’re working on a free subdomain for your first website, it may take even longer to get indexed, like 1-2 weeks.
The best advice is to just go about your work. Keep publishing, linking, and sharing on social media. Being active on your site and promoting it will send strong indications to Google that it needs to pay attention to what you’re doing.
What is Crawling?
Crawling (also referred to as ‘spidering’) is the process that web robots or artificial intelligence (AI) use to locate new web pages on the web. Bots follow hyperlinks to discover content on the web. This is the process of crawling and that’s how search engines find your blog posts.
While it would be nice if Google or Bing could crawl your sites almost instantly, it’s just not plausible since there are so many other web pages on the Internet.
There are over a billion websites with potentially 180 quadrillion web pages. Google only has a small percentage of them (60+ trillion) in its index since most exist in the deep web (what?!?!?). Bing possibly even fewer pages indexed!
This is why it can take some time for web pages to be discovered by search engines, which is pretty quick all things considered.
What’s Indexing?
The algorithms decide whether to include your blog posts after they are discovered via the process of crawling.
Search engines maintain a database index or info structure that is designed to improve the efficiency of information retrieval whenever a search is initiated. The process of including your web pages in the index is called indexing.
Content can be excluded from the index if it doesn’t meet a particular search engine’s standard. This rarely happens as long as you write decent content according to some basic rules. Even then, there’s still a lot of garbage online, so Google really only excludes the worst of the worst.
Technical SEO Issues
What if my site isn’t new? In this case, you may actually have a problem with your website. Whenever you suddenly start having indexing problems, it’s usually an issue with your site and often a technical one.
1. You Hit Your Crawl Budget
Search engines have massive amounts of web pages to crawl daily and perhaps, it just isn’t your turn yet. However, another reason why your blog post might not be indexed is if you’ve hit your “crawl budget”.
This is the number of web pages that Googlebot (AI) is willing to crawl every time it visits your site. There are a couple of factors that can influence how much Googlebot wants to crawl. These are a) how fast your web pages load and b) the size of your website.
Both factors affect the crawl rate and resource demand. Essentially, the heavier the workload or resource demand to crawl your web pages, the lower the time a bot spends doing so. So it would take longer for all your blog posts to be crawled if you keep exceeding your crawl budget.
Things like unnecessary redirects or redirect chains will deplete your crawl budget faster. For example, redirecting page A to B before getting to C, which is the actual replacement page.
Normally, you don’t have to concern yourself with crawl budget if you’ve got a smaller site (i.e. 1 – 200 pages). It’s mostly larger sites that have to worry about this.
Still, you should track your index coverage to make sure Google or Bing is including all your web pages. Sometimes your pages are indexed but they just aren’t in the top 100 search results, which is why you can’t see them.
Here’s how to check in Google Webmaster Tools.
Login to GSC (Google Search Console), select your website from the top left menu and then click ‘Coverage’. You’ll be presented with the option of sorting by all known pages, submitted web pages or sitemap.
Use the sitemap option if you’ve got a complete one. However, sorting by all known pages is best if you do not have a full sitemap. You can generate a sitemap for free if you have a smaller site.
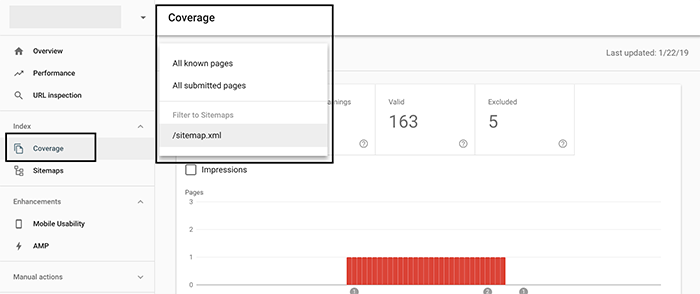
All is good if the number of pages on your domain is equivalent to the number of web pages in your GSC coverage stats.
If you see a large number of pages that are not indexed, you may need to make some structural changes to your site. That could include deleting old pages that don’t generate traffic and redirecting those links to relevant, more updated content so you don’t get a bunch of 404 errors. You might also rework those pages to optimize for keywords, and improve the content by adding more text, video, images, and outbound/internal links.
2. Robots.txt Error
The robots.txt file is a text file Webmasters use to tell or instruct search engine algorithms or bots on how to crawl and index their web pages. Your pages won’t be crawled if you accidentally disallowed Googlebot from accessing your site, which is a common issue.
The directives contained within the file are used to include or exclude content from their index with regards to your web pages and directories. So examine your robots.txt document to make sure it IS NOT set up like the following.
User-agent: *
Disallow: /
The asterisk means that it applies to all bots. The single forward slash means that no pages on the website should be crawled.
Your robots.txt file may be set up in this way, especially, if you hired a web designer to create your site. Some web developers do this in the design stage to prevent indexing while they’re working on your website. They may forget to delete or alter the directives within the file.
If you see this in your robots.txt file, simply remove the slash (/), and you’re good to go. It should look like this:
User-agent: *
Disallow:
3. Canonical Tag Error
Duplicate content within your website can cause the affected blog posts to be excluded from the index. The main reason this happens is when webmasters fail to properly implement the ‘rel=canonical’ HTML attribute. It’s used to tell search engine bots which page is the original or preferred version that you want to rank.
You can safely have duplicate content within your site if this tag is properly implemented. Every page should have a canonical tag as a rule of thumb. WordPress typically does this for you on autopilot.

The canonical page is always given ranking priority so search engines will often ignore duplicates or exclude them entirely from their index. Why rank a duplicate page when there’s already an original present?
4. Internal Linking Problems
Bots may ignore web pages that have no internal and/or external links. We refer to these pages in the SEO industry as ‘Orphan Pages’.
It’s difficult or impossible for AI to find your web pages when nothing is linking to them. Googlebot or Bingbot need to follow hyperlinks in order to discover content. You should always interlink your blog posts to avoid this problem. Even something simple like sharing a new blog post on social media can be an inbound link that gets your content discovered.
One of the easiest ways I’ve found that ensures all my web pages are interlinked is to use a related posts WordPress plugin like Yuzo.
No Keyword Focus?
I have found that some pages simply disappear from search engines because nobody cares about them, including myself. Some of my old content did not have a focus keyword, and is only about 1000 words long, so it doesn’t rank for anything at all. Even if it’s not ranked well, content can still be indexed, so why are these pages not indexed?
If I’m also not linking to those pages, then Google has no reason to crawl these pages. By not linking to them, I’m basically saying they are not important, so Google can ignore them. Without links going to those pages, or with very few links from equally unpopular pages, search spiders don’t actually see the pages.
Try improving the content to make it more keyword focused, link internally to these pages, or delete them altogether (or use a 301 permanent redirect)
Final Thoughts And A BONUS Tip
As you can see, there could be a number of reasons why your blog posts aren’t indexed. However, knowing how search engines work will make it easier to find and rectify any issues. Keep in mind that they have to deal with trillions of web pages, not just yours. So it can take a while for their robots get to you.
Bonus Tip – You can speed up indexing time by submitting your URL into Search Console (Webmaster Tools). Also, sharing your blog posts socially (i.e. tweeting), reducing load time etc. can be helpful. The goal is to do everything possible to reduce crawl demand and increase crawl rate for your site.

Nathaniell
What's up ladies and dudes! Great to finally meet you, and I hope you enjoyed this post. My name is Nathaniell and I'm the owner of One More Cup of Coffee. I started my first online business in 2010 promoting computer software and now I help newbies start their own businesses. Sign up for my #1 recommended training course and learn how to start your business for FREE!
 Find Offers & Products To Promote On Your Affiliate Website
Find Offers & Products To Promote On Your Affiliate Website
Leave a Reply